Welcome to the companion page for the “Efficient Formal Verification for the Linux Kernel”. This paper was accepted at the International Conference on Software Engineering and Formal Methods (SEFM 2019).
The last version of the paper is here.
The slides presented at SEFM are here.
The dot2c tool is here. It is a python script.
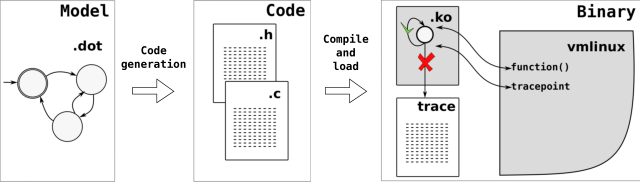
The code for the model Scheduling While in Atomic verification is here.
The code for the model Wake-up in Preemptive verification is here.
Both models can run on recent Linux kernel + PREEMPT_RT with the following options enabled:
CONFIG_PREEMPT_RT_FULL=y CONFIG_PREEMPTIRQ_TRACEPOINTS=y
The Need-resched Forces Scheduling set-up other than depending on the above configs, depends on the patchset that adds the tracepoints needed in the Linux Task Model, in the PREEMPT_RT mode. The kernel also needs to be configured as uni-processor (as a dependency for the task model).
Bug description
Problem 1
The preempt_irq tracepoint only traces in the disable <-> enable case. Which is correct, but think about this case:
THREAD IRQ
| |
preempt_disable() {
__preempt_count_add(1)
-------> smp_apic_timer_interrupt() {
preempt_disable()
do not trace because preempt count is >= 1
....
preempt_enable()
do not trace because preempt count is != 0
<------- }
trace_preempt_disable();
}
In words: if an IRQ takes place in between the disable and the trace, we might miss the preempt disable of an IRQ. A possible solution for this is to disable IRQs between the preempt_count_add/sub and the trace.
Problem 2
The preempt_irq tracepoint only traces in the disable <-> enable case. Which is correct, but think about this case:
THREAD IRQ
| |
preempt_disable_notrace() {
__preempt_count_add(1)
}
no preemptive section
-------> smp_apic_timer_interrupt() {
preempt_disable()
do not trace because preempt count is > 1
....
preempt_enable()
do not trace because preempt count is > 1
<------- }
preempt_enable_notrace() {
__preempt_count_sub(1)
}
In words: the preempt_disable_notrace() can hide a non-notrace (which could be traced, if it is in another context). Possible solution: have a per-cpu counter to count the traceable preempt_disable/enable, and use it to print or not.
BUG report and fixes
The problems above were reported to the Linux Kernel Mailing List (Linux kernel development list, the official way to communicate problems and patches), along with a possible fix. The WIP model was included in the report, as the reproducer for the problem. The report is here.
FAQ
Why not eBPF?
who said that? here is the PoC of dot2bpf.
Why did the Linux Task Model was not used in the SEFM 2019 paper?
This paper is a Future work of the ISORC 2019’s “Untangling the Intricacies of Thread Synchronization in the PREEMPT_RT Linux Kernel” paper! Unfortunately, the model was not ready to be verified in the kernel at the time that the SEFM paper was written. There are two main reasons:
1) The Linux Task Model (LTM) depends on some kernel patches to work, and also in the interpretation of some tracepoints data that was only implemented in user-space when the paper was being written.
2) The model as is in the current date was modeled to describe the behavior of one single task, concerning other tasks of higher, lower, and equal priority. For the purpose of monitoring the Kernel behavior, the model needs to be modified to monitor any task running. This requires some modeling effort, but it might even reduce the number of states.
However, as the verification is made in constant time for each event occurrence – O(1), two models with the same event set will present a similar overhead, independently of the number of states and transitions. The Need Re-Sched (NRS) model uses all the but the (very low frequency) NMI events of the LTM, so it is a good preview of the LTM overhead. Making the LTM is the primary motivation for efficient verification and is a high-priority future work.
How to deal with the synchronization of events?
Taking the following excerpt from the sample code:
int curr_state = get_curr_state(ver);
int next_state = get_next_state(ver, curr_state, event);
if (next_state >= 0) {
set_curr_state(ver, next_state);
It might be the case that the current task suffers preemption between get_next_state() and set_curr_state(). Moreover, in a multiprocessor system, the following behavior can take place as well:
CPU 0 | CPU 1
------------------------------------------------------------------
get_curr_state(ver) |
return A |
get_next_state(ver, A, event) |
returns B |
| get_curr_state(ver)
| returns A
set_curr_state(B) |
| get_next_state(ver, A, event)
WRONG! Curr state is B.
So, yes! Synchronization is needed.
But why does not the verification code use synchronization?
The short answer is: The synchronization between the real event and the trace of the event is provided in the already existing kernel code (or at least should already be).
Generalizing the problem, it is possible to take as an example the actual wakeup of a thread (set it as running) and its trace (sched:sched_wakeup).
kernel/sched/core.c:
ttwu_do_wakeup() {
[....]
p->state = TASK_RUNNING;
trace_sched_wakeup(p);
[...]In the code, both cases previously illustrated could happen: A preemption could happen in the middle, and a task could be placed to run before the trace of its activation appears in the trace.
However, this unreasonable effect does not happen in practice because the task’s state is already protected by the rq_lock, providing consistency locally (because preemption is disabled) and globally (because it is a spinlock). In practice, the trace of the event and the event itself are already protected against concurrency because of the natural need for synchronization of the event itself.
There are cases in which the synchronization between the event and the trace (or monitoring) should be enforced. That is the case of the bug with the preempt_disable/enable event reported (and acknowledged by developers as a bug) during the development of this paper.
Still, the following question might correctly be raised
Can the synchronization impact the efficiency of the presented method?
Yes, synchronization impacts in the efficiency. The main point, however, is that the synchronization is required for a tracing-based approach too (the main comparison of the paper) as well as for a hard-coded method. The mentioned bug is an example of the trace case, and the lockdep_lock is an example for an in-kernel hard-coded method (see the function grab_lock() on the kernel/locking/lockdep.c Linux kernel code).
With this regard, the proposed approach adds an indirect benefit with regard to tracing: by incurring lower overhead, the synchronization contention will be lower as well.
Additionally, ftrace uses only one synchronization on its “recording” part: preemption_disable_notrace. No other synchronization method is used (not even allowed to be used). This is good evidence that no complex synchronization will be required for the proposed approach as well.
Regarding the comparison of the proposed method to other related work presented in the paper
The paper mentions other methods that use Linux kernel trace and automata. For example, SABRINE and TIMEOUT. SABRINE and TIMEOUT, however, have a different goal: they trace system execution to find code patterns in a sub-system. When a pattern is found, they aggregate the pattern in a node, with edges connecting “patterns”, creating an automaton that reduces the state-space of the system. The automata used later in a state-aware robustness testing of operating systems.
Although related, these papers have a different goal, hence it is not fair to conduce a performance evaluation. Still, these papers bases on ftrace execution and our results already compare the same subsystem to our approach, demonstrating the efficiency of our method. Still, our method does not apply to SABRINE and TIMEOUT, so it is not possible to say it “outperforms” or that it could “improve” those papers. At most, our approach could be used to inject code/improve tests in the kernel for the later state aware robustness testing part.
Why NRS was not used for throughput evaluation?
The NRS model is limited to the single-core case, which is a limitation of the LTM at the moment in which the paper was written. Moreover, it uses only tracepoints, while the SWA uses both tracepoints and function trace, representing so a more “extensive” use-case. The most high-frequency events in both cases are the same: IRQ and PREEMPTION control.
Why not use parametric and/or timed automata?
Both parametric and timed automata are important and challenging future work. As a guess – because this still needs to be developed – the parametric automata might be easier than the timed one. The main reason is that, in code, the parameters will become “ifs”, which are lightweight. The timed one will certainly require more control.
Why not compare the in-kernel approach with a complete verification in user-space?
The steps for a user-space verification are: 1) trace data in the kernel, 2) copy the data to user-space, and 3) process it. Our evaluation compares our complete verification to only the first of the three steps required for verification in user-space. Hence, it is already an unfair comparison in the sense that our approach does all the steps (the full verification) while comparing it with one out of three steps for the user-space.
For the matter of curiosity, the user-space processing of the automata in reference 30 of the paper says:
“Due to the high granularity of data, a typical 30 seconds trace of the system running cyclictest as workload, generates around 27000000 events, amounting 2.5 GB of data. To avoid having to collect the trace buffer data very frequently, a 3 GB trace buffer was allocated”
and…
“This is a critical point, given the number of states in the model, and the amount of data from the kernel. On the adopted platform, each GB of data is evaluated in nearly 8 seconds.”
The extra overhead on saving larger data and transferring/processing in user-space will certainly increase the benefits on an in-kernel approach. The comparison is planned to be included in an extended version of the paper.
I cannot see the NRS model in the printed version of the paper
While we tried to increase the image fonts, due to the limited space in the paper, if the quality of the printer is not high, the NRS model does not look fine. The Figure in the paper is in the vectorial format, so it is possible to zoom in and see all the details. If you prefer, click on the image below to see the high-resolution image.
